批量查询订单(总部)-测试:有赞云数据集成到敦煌种业先锋
在现代企业的运营中,数据的高效流动和准确对接至关重要。本文将分享一个实际运行的系统对接集成案例:如何通过轻易云数据集成平台,将有赞云的数据批量集成到敦煌种业先锋系统中,实现订单信息的高效管理。
项目背景
在本次项目中,我们需要实现从有赞云批量查询订单,并将这些订单数据可靠地写入到敦煌种业先锋系统。该方案被命名为“批量查询订单(总部)-测试”,旨在确保数据在两个平台之间无缝传输,提升整体业务处理效率。
技术要点
-
高吞吐量的数据写入能力
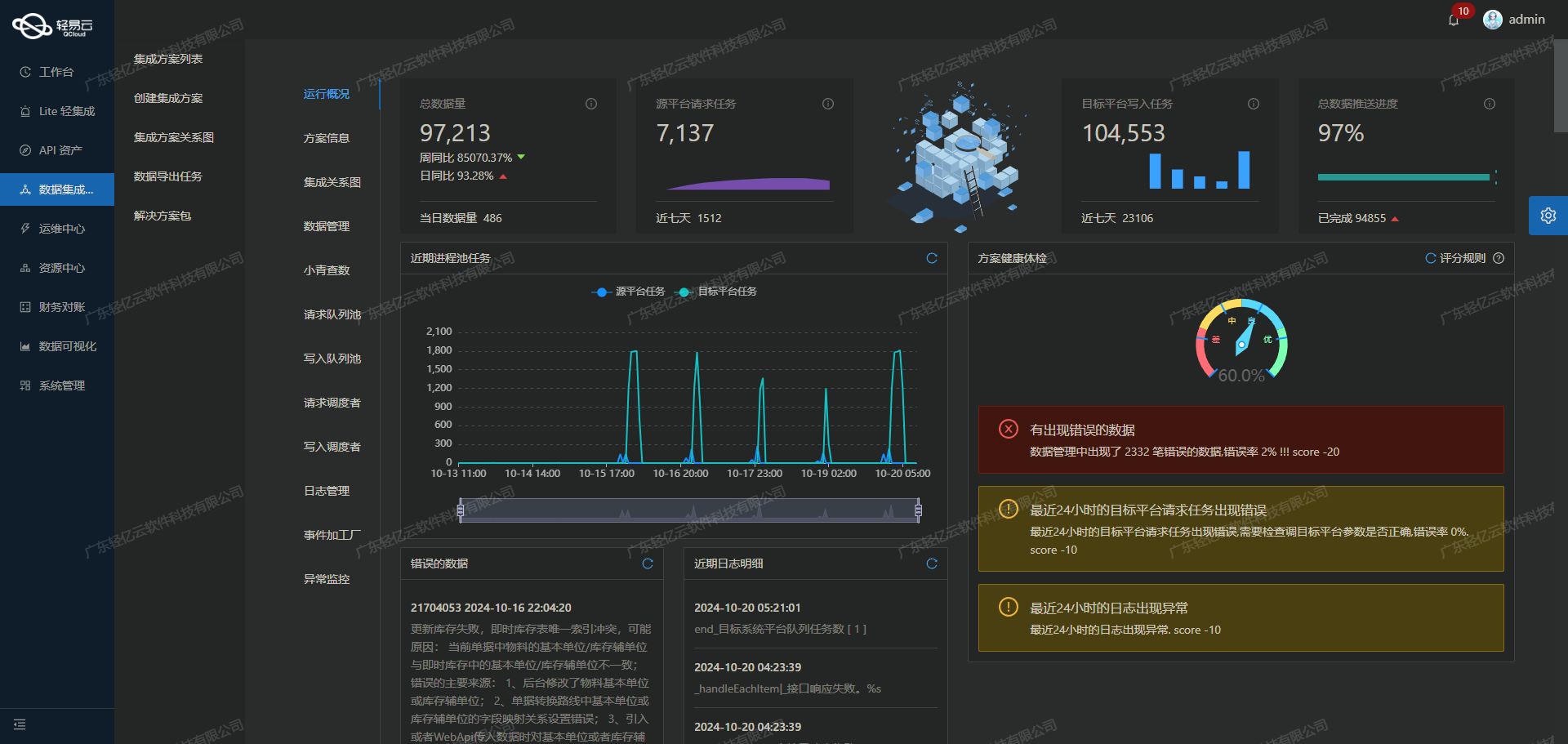
为了应对大量订单数据的快速处理需求,我们利用轻易云平台提供的高吞吐量数据写入能力,使得大量订单能够迅速且稳定地写入到敦煌种业先锋系统。这一特性极大地提升了数据处理时效性,确保业务流程顺畅进行。 -
实时监控与告警系统
在整个数据集成过程中,实时监控和告警系统发挥了关键作用。通过集中监控任务状态和性能,我们能够及时发现并解决潜在问题,保证数据传输过程中的透明度和可靠性。 -
API资产管理功能
有赞云与敦煌种业先锋均提供了强大的API资产管理功能,通过统一视图和控制台,我们可以全面掌握API使用情况,实现资源的高效利用和优化配置。这不仅简化了接口调用过程,还提高了整体操作效率。 -
自定义数据转换逻辑
由于有赞云与敦煌种业先锋的数据结构存在差异,我们采用轻易云平台支持的自定义数据转换逻辑,对获取的数据进行必要的格式转换,以适应目标平台的要求。这一灵活性使得我们能够根据具体业务需求进行调整,确保每条数据信息准确无误地传递。 -
分页与限流处理
在调用有赞云接口(/youzan.trades.sold.get.4.0.4)时,需要特别注意分页和限流问题。我们设计了一套机制来有效处理这些问题,避免因请求过多导致接口调用失败,从而保障了数据抓取过程的稳定性。 -
异常处理与错误重试机制
数据对接过程中难免会遇到各种异常情况,为此我们实现了一套完善的异常处理与错误重试机制。当出现网络波动或其他不可预见的问题时,该机制能够自动识别并重新尝试传输,最大程度上减少因意外情况导致的数据丢失风险。
通过上述技术手段,本次“批量查询订单(总部)-测试”方案成功实现了有赞云与敦煌种业先锋之间的数据无缝对接。在后续章节中,我们将详细介绍具体实施步骤及技术细节。
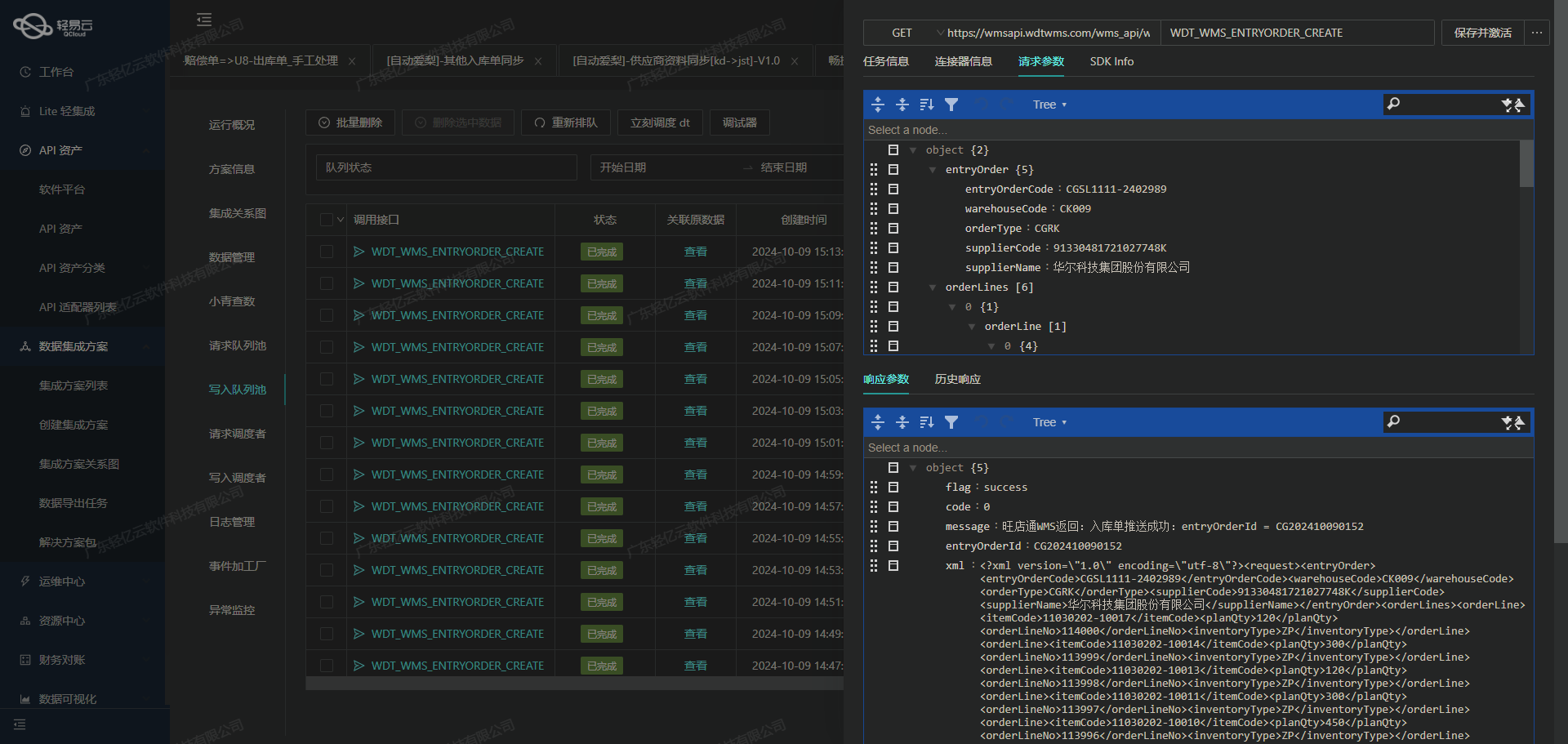
调用有赞云接口/youzan.trades.sold.get.4.0.4获取并加工数据
在数据集成过程中,调用源系统的API接口是至关重要的一步。本文将详细探讨如何通过轻易云数据集成平台调用有赞云接口/youzan.trades.sold.get.4.0.4来获取订单数据,并进行初步的数据处理。
接口调用配置
首先,我们需要配置元数据,以便正确地调用有赞云的API接口。以下是关键的元数据配置项:
- API路径:
/youzan.trades.sold.get.4.0.4 - 请求方法:
GET - 请求参数:
tid(订单号): 用于指定查询的订单。page_no(页码): 分页查询时使用,默认值为1。page_size(每页数量): 每次查询返回的记录数,默认值为100。
{
"api": "/youzan.trades.sold.get.4.0.4",
"method": "GET",
"request": [
{"field": "tid", "label": "订单号", "type": "string", "value": ""},
{"field": "page_no", "label": "页码", "type": "string", "value": "1"},
{"field": "page_size", "label": "每页数量", "type": "string", "value":"100"}
]
}数据分页与限流处理
在实际操作中,可能会遇到大量订单数据,这时需要通过分页机制来逐步获取所有数据。我们可以利用上述配置中的page_no和page_size参数进行分页控制。此外,为了避免触发API限流机制,需要合理设置请求频率。
示例代码片段(伪代码):
def fetch_orders(page_no):
response = call_api("/youzan.trades.sold.get.4.0.4", {
'tid': '',
'page_no': page_no,
'page_size': '100'
})
return response['orders']
# 分页获取所有订单
all_orders = []
for page in range(1, total_pages + 1):
orders = fetch_orders(page)
all_orders.extend(orders)数据清洗与转换
从有赞云获取的数据通常需要进行清洗和转换,以适应目标系统的数据结构。例如,可以对时间格式、字段名称等进行标准化处理。
示例代码片段(伪代码):
def clean_order_data(order):
# 转换时间格式
order['created_at'] = convert_time_format(order['created_at'])
# 重命名字段
order['order_id'] = order.pop('tid')
return order
cleaned_orders = [clean_order_data(order) for order in all_orders]自动填充响应与异常处理
为了提高效率,可以启用自动填充响应功能,使得每次请求后自动解析并存储返回的数据。同时,应实现异常处理机制,如重试策略,以确保在网络波动或其他异常情况下仍能稳定获取数据。
示例代码片段(伪代码):
def call_api_with_retry(api_path, params, retries=3):
for attempt in range(retries):
try:
response = call_api(api_path, params)
if response:
return response
except Exception as e:
log_error(e)
if attempt == retries - 1:
raise e
response = call_api_with_retry("/youzan.trades.sold.get.4.0.4", {'tid': '', 'page_no': '1', 'page_size': '100'})定时任务与监控告警
为了确保定期抓取最新的订单数据,可以配置定时任务,例如每天零点执行一次。同时,通过平台提供的监控和告警系统,实时跟踪任务状态和性能,及时发现并解决潜在问题。
定时任务配置示例:
{
"crontab":"0 0 * * *",
...
}综上所述,通过合理配置元数据、实现分页与限流、进行数据清洗与转换、启用自动填充响应及异常处理,并结合定时任务与监控告警功能,可以高效稳定地从有赞云获取并加工订单数据。这一过程不仅提升了业务透明度和效率,也为后续的数据集成奠定了坚实基础。
集成方案:批量查询订单(总部)-测试
在数据集成过程中,第二步是将源平台的数据进行ETL转换,确保数据能够符合目标平台的API接口格式要求并成功写入。本文将聚焦于如何将已经集成的源平台数据转换为敦煌种业先锋API接口所能够接收的格式,并最终写入目标平台。
数据请求与清洗
首先,从有赞云接口youzan.trades.sold.get.4.0.4批量查询订单数据。为了确保不漏单,我们需要处理接口的分页和限流问题。通过定时任务可靠地抓取有赞云接口数据,并实时监控与日志记录,保证数据抓取过程的稳定性和完整性。
数据转换与写入
-
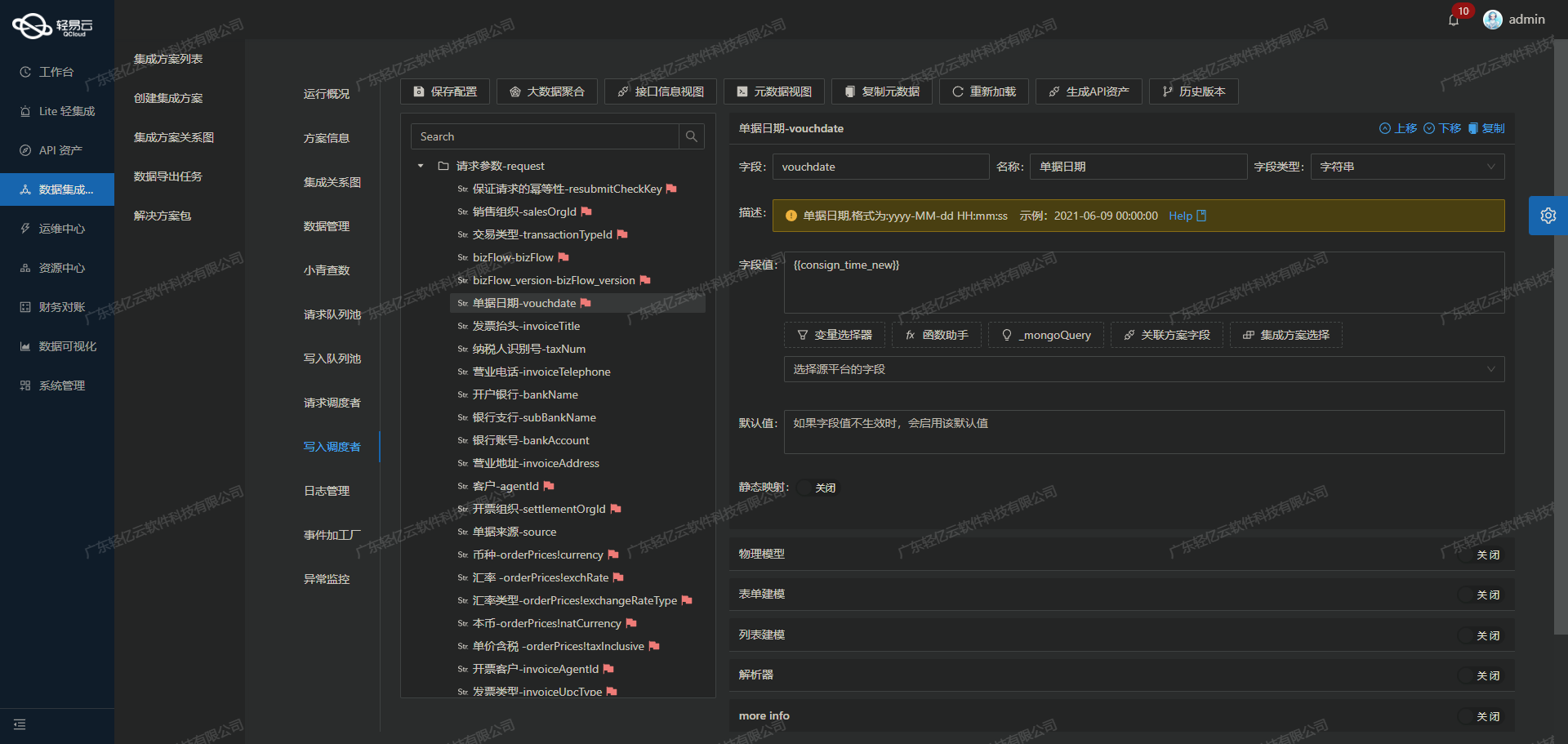
配置元数据映射
根据敦煌种业先锋API接口要求,需要对从有赞云获取的数据进行字段映射和格式转换。以下是元数据配置示例:
{ "api":"/Api/QEasyCloud/OtOOrder", "method":"POST", "request":[ {"field":"OrderNo","label":"订单号","type":"string","value":"{bfn_num}"}, {"field":"OrderTime","label":"下单时间","type":"string","value":"{{order_info.created}}"}, {"field":"StoreId","label":"门店id","type":"string","value":"{{order_info.node_kdt_id}}"}, {"field":"CustomerId","label":"客户id","type":"string","value":"{{buyer_info.yz_open_id}}"}, {"field":"ProductName","label":"产品名称","type":"string","value":"{orders_newtitle}"}, {"field":"ProductSPec","label":"产品编码","type":"string","value":"{orders_newSpecNo}"}, {"field":"Num","label":"数量","type":"string","value":"{orders_num}"}, {"field":"Amount","label":"金额","type":"string","value":"{orders_price}"}, {"field":"Name","label":"收货人姓名","type": "string", "value": "{{address_info.receiver_name}}"}, {"field": "MobilePhone", "label": "收货人电话", "type": "string", "value": "{{address_info.receiver_tel}}"}, {"field": "ProvinceName", "label": "省", "type": "string", "value": "{{address_info.delivery_province}}"}, {"field": "CityName", "label": "市", "type": "string", "value": "{{address_info.delivery_city}}"}, {"field": "DistrictName", "label": "区", "type": "string", "value": "{{address_info.delivery_district}}"}, {"field": "Address", "label": "详细地址", "type": "string", "value": "{{address_info.delivery_address}}"} ] } -
自定义数据转换逻辑
为了适应特定业务需求和数据结构,可以自定义数据转换逻辑。例如,将有赞云的订单时间字段
created转换为符合敦煌种业先锋API要求的时间格式;将客户ID、门店ID等字段准确映射到目标系统所需字段。 -
处理异常与错误重试机制
在数据写入过程中,可能会遇到网络波动、目标系统响应超时等异常情况。需要实现异常处理与错误重试机制,以确保数据能够最终成功写入目标系统。通过设置合理的重试次数和间隔时间,可以提高系统的鲁棒性。
-
高吞吐量的数据写入
敦煌种业先锋API支持高吞吐量的数据写入能力,使得大量订单数据能够快速被集成到目标平台中。这不仅提升了数据处理的时效性,也能满足业务对实时性的数据需求。
-
批量集成与监控
批量集成可以有效提高效率,减少单次请求的开销。在批量操作过程中,通过提供集中的监控和告警系统,实时跟踪每个任务的状态和性能,及时发现并处理潜在问题。
-
定制化数据映射对接
根据实际业务需求,对不同字段进行定制化的数据映射。例如,将有赞云中的收货人信息、配送地址等详细信息准确映射到敦煌种业先锋系统对应字段,确保每个订单信息完整无误。
实现步骤总结
- 从源平台(有赞云)批量查询订单,并处理分页和限流。
- 清洗并转换获取的数据,根据元数据配置进行字段映射。
- 自定义转换逻辑以适应特定业务需求。
- 实现异常处理与错误重试机制。
- 高效批量写入到目标平台(敦煌种业先锋)。
- 提供实时监控和告警,确保整个过程顺利完成。
通过以上步骤,可以实现从有赞云到敦煌种业先锋API接口的数据无缝对接,确保每个环节都高效、稳定运行。